
BESS(Back-End Study Space)
비지도학습 (Unsupervised Learning) 본문
2020/11/29 - [데이터 분석 입문/머신러닝] - 회귀 (Regression)
회귀 (Regression)
2020/11/29 - [데이터 분석 입문/머신러닝] - 분류 (Classification) 분류 (Classification) 2020/11/29 - [데이터 분석 입문/머신러닝] - 지도학습 (Supervised Learning) 지도학습 (Supervised Learning) 2020/1..
leeezxxswd.tistory.com
#1. 비지도학습 (Unsupervised Learning)
- 지도학습과는 달리, 타겟값(Y)이 없는 입력 데이터(X)만을 학습하는 방법
- 입력 데이터에 내재되어 있는 특성을 찾아내는 용도
#2. 비지도학습의 종류

1. 군집화 (Clustering) : 유사한 포인트들끼리 그룹을 만드는 방법
- Model or Structure of clusters : Clusters IDs for each point

2. 잠재 변수 모델 (Latent Variable Model) : 표현된 데이터 속에 내재되어 있는 요인을 찾는 것
- 현재 데이터 속에 내재되어 있는 정보가 관측되지 않은 상태에서 z라는 내재되어 있는 변수를 찾아낸다.
- 종류
1)주성분 분석(Principal Component Analysis, PCA)
2) 특이값 분해(Singular Value Decomposition, SVD)
3)비음수 행렬 분해(Nonnegative Matrix Factorization, NMF)
4)잠재 디리슐레 할당(Latent Dirichlet Allocation, LDA)
- 예 ) Topic Modeling : 문서에서 주제를 찾는 모델링
☞ 주어진 문서에 존재하는 단어들의 분포를 보고 주제(latent variable)별로 분류하고, 해당 단어가 그 주제에 어느정도 기여하고 있는지 알아낸다.
3. 밀도 추정(Density Estimation) : 관측된 데이터를 이용하여 데이터 생성에 대한 확률밀도함수를 추정
- 가우시안 혼합 모델(Gaussian Mixture Model, GMM) : 정규분포
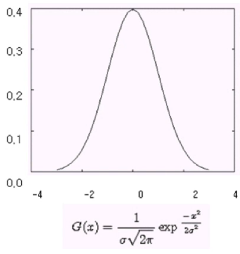 수학점수만 고려하는 정규분포 |

|
- 커널 밀도 추정 (Kernel Density Estimation, KDE) : '커널'이라고 하는 몇 가지 분포를 이용해서 데이터를 추정

|
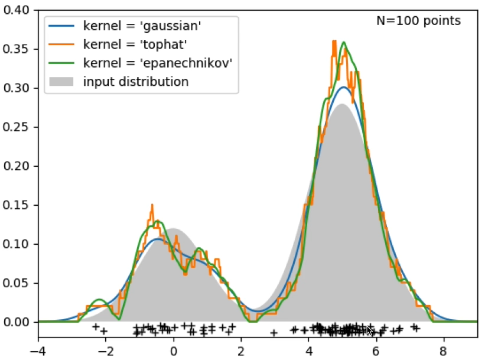 - 정규분포(회색) 상에서 데이터를 샘플링한 모습 |
4. 이상치 탐지 (Novelty (or Anomaly) Detection) : 다른 포인트들과 비교하여 많이 벗어나 있는 포인트를 찾아내기
- 종류
1) Local Outlier Factor (LOF)
2) Isolation Forest
3) One-class Support Vector Macine (SVM)
- 예 ) LOF

- 대다수의 점들과 모여있지 않은 주변에 떨어진 점들의 수가 LOF모델로 계산 할 수 있는 점수를 나타냄
- 점수가 큰 것들을 데이터 포인트들과 떨어져 있는 anomaly로 생각
5. 인공신경만 기반 비지도 학습
- 예 ) Generative Adversarial Network (GAN)

- training set를 가지고 가짜 데이터(random noise)를 실제 데이터처럼 비슷하게 만들어내는 것
- Discriminator로 Real / Fake 를 가려내는 것으로 이것이 지도학습이라고 논할 수 있으나, 'GAN'의 주 목적은 Fake image 만드는 것을 학습시키는 것
** 적용 예시

- training set
1) 안경을 쓴 남자의 사진
2) 안경을 쓰지 않은 남자의 사진
3) 안경을 쓰지 않은 여자의 사진
- Generator : 1) - 2) + 3)
▶ 1) - 2) → 안경만 남음
→ + 3) → 안경을 쓴 여자의 사진(fake image)
'데이터 분석 입문 > 머신러닝' 카테고리의 다른 글
| 신경망모델(Neural Networks)과 딥러닝(Deep Learning) (0) | 2020.12.04 |
|---|---|
| 강화학습 (Reinforcement Learning) (0) | 2020.11.30 |
| 회귀 (Regression) (0) | 2020.11.29 |
| 분류 (Classification) (0) | 2020.11.29 |
| 지도학습 (Supervised Learning) (0) | 2020.11.29 |



