
BESS(Back-End Study Space)
머신러닝(Machine Learning) 본문
#1. 머신러닝 (Machine Learning)
- 컴퓨터가 데이터를 학습하는 알고리즘과 기술을 통칭
- 컴퓨터과학과 수학, 통계가 모두 필요한 학문
- 현상을 설명하거나 미래를 예측하는 용도로 활용
- 예) 스팸을 분류하는 규칙을 만들어 모델화
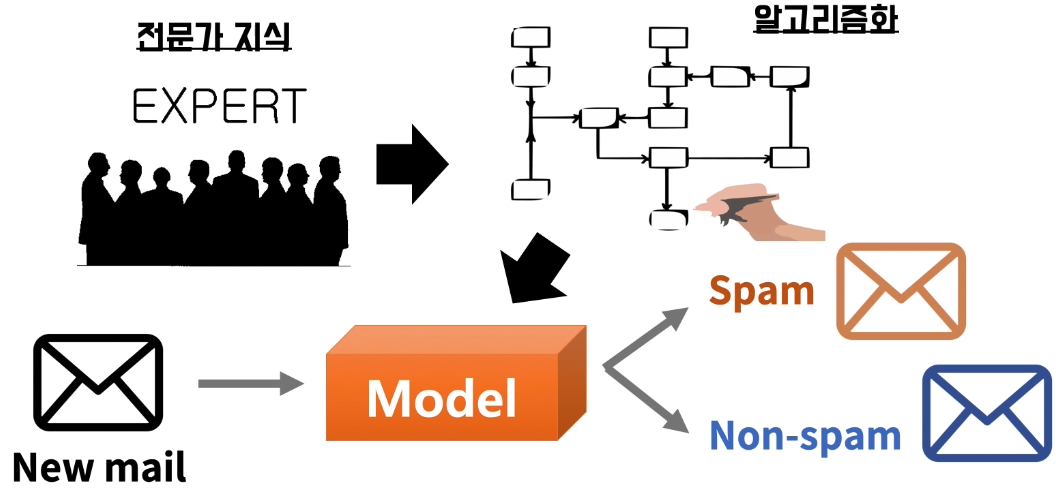
문제점
- 전문가들의 지식을 빈틈없이 규칙 집합(가정과 그에 따른 결과)으로 표현 가능한가?
- 새로운 지식의 업데이트는 용이한가?
- 예) 머신러닝 기반 스팸 필터링
데이터를 학습하여 생성된 모델을 이용하여 새로운 메일/문자의 스팸 여부를 예측

▶ 사람이 직접 스팸 분류를 하는 것에 비해,
1. 덜 지치면서 스팸 분류 가능
2. 더 빠르게 스팸 분류 가능
▶ 규칙 기반의 스팸 필터링 모델에 비해,
1. 여러 인자(특수문자, 특수단어.. 등)를 동시에 고려하며 스팸 분류 가능
2. 더 많은 유형의 스팸을 분류할 것으로 기대됨
※ 그러나 두 방법에 비해 ※
더 많은 양의 데이터와 더 많은 컴퓨팅이 필요
☞ 빅데이터, 고성능 컴퓨팅 파워 그리고 이것들을 처리할 수 있는 알고리즘들이 존재 !
#2. 머신러닝의 세 가지 유형
1. 지도학습 (Supervised Learning)
2. 비지도학습 (Unsupervised Learning)
3. 강화학습 (Reinforcement Learning)
'데이터 분석 입문 > 머신러닝' 카테고리의 다른 글
| 강화학습 (Reinforcement Learning) (0) | 2020.11.30 |
|---|---|
| 비지도학습 (Unsupervised Learning) (0) | 2020.11.30 |
| 회귀 (Regression) (0) | 2020.11.29 |
| 분류 (Classification) (0) | 2020.11.29 |
| 지도학습 (Supervised Learning) (0) | 2020.11.29 |
'데이터 분석 입문/머신러닝' Related Articles
more



